We parallelized the incremental heuristic search D*Lite, which has applications in real-time terrain traversal. We ran our implementation on the GHC 5201/5205 machines using OpenMP and POSIX threads.
Summary
Background
Our algorithm takes in a map, a start vertex, and a goal vertex, and outputs a path from start to goal with incomplete knowledge of the map. The graph which we run our graph search on is a mesh-like 2D map, containing obstacles (represented by an edge weight of infinity). To traverse the graph from start to goal, we calculate a proposed shortest path using a heuristic which adheres to the triangle inequality (Euclidean distance), much like in A*. We advance through the map on this shortest path until we find we have run into an obstacle. At this time, we update all of our edge weights with this new data, compute a new shortest path, and continue running until completion.

Figure 1: An example of a traversal of a 20x20 grid, as generated by our visualizer.

Figure 2: An example of a completed traversal of a 1000x1000 grid.
The key operations lie in the computeShortestPath() function. To determine the next vertex we visit, we maintain a heap containing all possible vertices we can visit and their projected path distance. In the occasion of running into an obstacle, we must update the costs of the projected paths of all elements in the heap. We do this by popping off a vertex off the heap, updating the edge weights of all its predecessors, and putting this back onto the heap. We then continue popping elements off the heap and updating costs until either the cost of the vertex at the top of the heap is greater than the cost of the vertex we are currently at, or until the cost of the current vertex to the goal doesn’t equal the cost of the vertex’s successors plus the cost from the current vertex to the successor.
The biggest problem with parallelizing D*Lite is its inherently sequential nature as both incremental and a graph search. Even updating the vertex costs must be done in a recursive manner, since we always pop off the next vertex to update off the heap. However, when looking at all of a vertex’s predecessors to update those costs, we can perform these operations in parallel. Although speedup from parallelizing these operations seems negligible in the 2D case, when scaled up to 3D applications where there are more than only 4 directions to go in, we might see significant speedup. When addressing an infinite space of directions to go, we would see an increase both accuracy and efficiency due to the power of splitting up the work of processing each direction.
Figure 1: An example of a traversal of a 20x20 grid, as generated by our visualizer.
Figure 2: An example of a completed traversal of a 1000x1000 grid.
The key operations lie in the computeShortestPath() function. To determine the next vertex we visit, we maintain a heap containing all possible vertices we can visit and their projected path distance. In the occasion of running into an obstacle, we must update the costs of the projected paths of all elements in the heap. We do this by popping off a vertex off the heap, updating the edge weights of all its predecessors, and putting this back onto the heap. We then continue popping elements off the heap and updating costs until either the cost of the vertex at the top of the heap is greater than the cost of the vertex we are currently at, or until the cost of the current vertex to the goal doesn’t equal the cost of the vertex’s successors plus the cost from the current vertex to the successor.
The biggest problem with parallelizing D*Lite is its inherently sequential nature as both incremental and a graph search. Even updating the vertex costs must be done in a recursive manner, since we always pop off the next vertex to update off the heap. However, when looking at all of a vertex’s predecessors to update those costs, we can perform these operations in parallel. Although speedup from parallelizing these operations seems negligible in the 2D case, when scaled up to 3D applications where there are more than only 4 directions to go in, we might see significant speedup. When addressing an infinite space of directions to go, we would see an increase both accuracy and efficiency due to the power of splitting up the work of processing each direction.
Memory and Locality
The original D*Lite algorithm that we ran as reference made little use of locality of memory. The map was divided into cells, with each cell holding a large struct containing the moves, successors, heuristic values, searchtree and trace pointers, etc. Every time a cell was operated on, a few memory stores would be sent to the cell struct. This was convenient due to the fact that all of the memory locations for that particular cell are in the same place, so the chance of them all being on the same cache line is large.
However, the efficiency goes down when many cells are accessed in a row; the cells may be close together on the map, but due to the layout of the struct, two cells’ corresponding structs may not be on the same cache line. Thus, every time a new cell was accessed, it is probable that the cache missed and the line would need to be loaded. Due to the memory access patterns of the algorithm, each cell is not accessed that many times.
In order to attempt to better utilize locality, we changed the memory model and rewrote the entire algorithm (including libraries) to account for the new memory model. The new memory model takes each similar element from the old cells’ structs and coalesces them into a single block of memory. For example, all of the heuristic values are combined such that maze[0,0] and maze[0,1] have heuristic values that are consecutive in memory. While this means that accessing a single cell’s data requires going to a different part of memory for each cell’s field, consecutive accesses to different cells in a region will cause better cache locality. Since the access patterns usually include the 4 neighbors of any particular cell, their data will be close together in memory. In addition, the chance of the next access pattern being the 4 neighbors of one of these cells is also high, which further takes advantage of locality.
However, the efficiency goes down when many cells are accessed in a row; the cells may be close together on the map, but due to the layout of the struct, two cells’ corresponding structs may not be on the same cache line. Thus, every time a new cell was accessed, it is probable that the cache missed and the line would need to be loaded. Due to the memory access patterns of the algorithm, each cell is not accessed that many times.
In order to attempt to better utilize locality, we changed the memory model and rewrote the entire algorithm (including libraries) to account for the new memory model. The new memory model takes each similar element from the old cells’ structs and coalesces them into a single block of memory. For example, all of the heuristic values are combined such that maze[0,0] and maze[0,1] have heuristic values that are consecutive in memory. While this means that accessing a single cell’s data requires going to a different part of memory for each cell’s field, consecutive accesses to different cells in a region will cause better cache locality. Since the access patterns usually include the 4 neighbors of any particular cell, their data will be close together in memory. In addition, the chance of the next access pattern being the 4 neighbors of one of these cells is also high, which further takes advantage of locality.
Approach
We started with parallelization on the CPU, using OpenMP and Pthreads on separate occasions on the Gates 5201/5205 machines. Since we only ever want up to 4 threads in the 2D case, we decided against using CUDA threads for the moment, as the vast majority would be idle. We also knew that the workload performed by each thread would be approximately the same since the workload was reasonably fast with essentially a sequence of memory accesses, so we were not very concerned with the possibility of an overly unbalanced workload.
For the sake of analysis, we ran several iterations of our code and compared it against the original D*Lite procured from here. We used OpenMP to parallelize both the original D*Lite and our implementation of D*Lite with an improved memory model. We also used Pthreads in our implementation with the improved memory model. We tested our code for correctness by generating visuals at each iteration where the target found an obstacle and was forced to recalculate the costs of the shortest paths and comparing our maps against the original implementation. We also timed our code, timing both the entire traversal as well as the single iterations of recomputing shortest paths.
For the sake of analysis, we ran several iterations of our code and compared it against the original D*Lite procured from here. We used OpenMP to parallelize both the original D*Lite and our implementation of D*Lite with an improved memory model. We also used Pthreads in our implementation with the improved memory model. We tested our code for correctness by generating visuals at each iteration where the target found an obstacle and was forced to recalculate the costs of the shortest paths and comparing our maps against the original implementation. We also timed our code, timing both the entire traversal as well as the single iterations of recomputing shortest paths.
Results
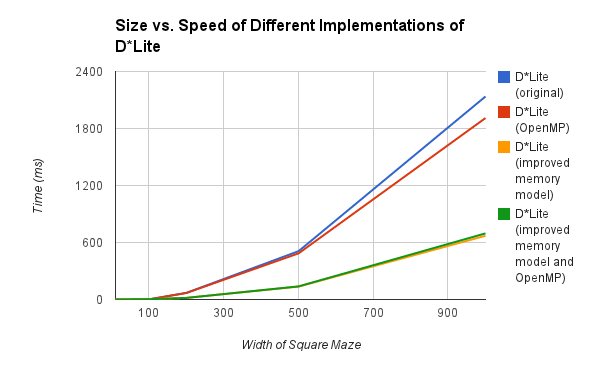
Figure 3: Graph of our implementations and comparison of speeds.

Figure 4: Data chart of the time to traverse across the map. Times are in milliseconds.
The results we obtained were far from what we expected. The addition of parallel code did not do much to improve the speedup, if it helped at all. The switching of memory models did give great speedup over the original version, but neither OpenMP nor POSIX threads were able to advance the speedup much further.
OpenMP
We found that OpenMP attained a minor speedup when implemented on the original memory model, but no speedup when implemented on the updated memory model. On the original memory model, we noted that speedup was as expected. Since many of the vertices had only a few predecessors (likely 2~3), and since the remainder of the algorithm had to be sequential, our speedup of approximately 5% was expected.
When implemented on the updated memory model, we hypothesize that we did not see any significant results due to the fact that there was less thrashing, and so less latency can be hidden. The benefit of a 2D graph search is the inherent locality, since we are often searching in the vicinity of the current vertex we are on. In the original memory model, we had cache thrashing which increased latency, and OpenMP had the opportunity to hide that latency. However, in our new memory model, we no longer have such frequent cache misses, so no latency is hidden. As the operations we are parallelizing already have a short computation time, we lose any benefit from our parallelization.
Overall, there may have been some overhead from OpenMP we may have missed, but the data implies that with higher granularity, we might see a considerable speedup.
POSIX Threads
The results from POSIX threads showed that the benefits of speedup were greatly overshadowed. In order to implement Pthreads, it was necessary to allocate a struct to hold arguments, call Pthread_create(...) and call Pthread_join(...). Each of these parts took more time to do than the original code did for the entire section. On average, the original code could run an iteration in 0.001 ms, and each of the above instructions took at least .01 ms. In addition, the threads did not finish at the same time; the threads would begin at different times but would not finish at the same staggered rate. For example, if one thread started .002 ms later than a previous one, then if the workload is equal then we would expect a similar offset for finishing. However, the offset grows to 0.03-0.05 ms by the end, suggesting that perhaps another hidden conflict is happening. One possibility could be the serialization of memory accesses; since the parallelizable code is mostly memory accesses, it’s possible that the threads wait for each other. One other possibility that is not as easily tested is cache thrashing. If the threads happen to be accessing the same cache lines, then they may invalidate each other and create more overhead.
In total, implementing POSIX threads increased the runtime of the code greatly. It seems that the overhead of managing threads, even if just 4, overshadows the benefits of the parallelism gained. These results add to the conclusion that, at least with a small search space and low iteration runtime, POSIX threads only decrease the amount of speedup.
Conclusion
In summary, based on our results we found that not much parallelism could be exploited in D*Lite due to its inherently sequential nature. The major source of speedup was due to improving the memory model to reduce cache misses. The parallelism we could work with was updating the shortest path costs of our visited vertices. From this, we found a minor speedup from OpenMP on the original memory model, but none on our updated memory model. In addition, we found a major slowdown from implementing pthreads.
Our data might imply that higher granularity may show immense speedup. Since our current model assumes a 2D map with only 4 directions to look in, we have a very coarse granularity. However, in the 3D situation, or even in a 2D case with a wider reach and more directions to look in, we can increase granularity and have much better speedup. Thus, the next step our project might point us in is towards greater thread usage with OpenMP, or possibly CUDA threads.
Our data might imply that higher granularity may show immense speedup. Since our current model assumes a 2D map with only 4 directions to look in, we have a very coarse granularity. However, in the 3D situation, or even in a 2D case with a wider reach and more directions to look in, we can increase granularity and have much better speedup. Thus, the next step our project might point us in is towards greater thread usage with OpenMP, or possibly CUDA threads.
References
Division of Work
Visualizer/Test Harness: Sarah
OpenMP on original memory model: Peter
Improved Memory Model Implementation: Peter
OpenMP on Improved Memory Model: Sarah
Pthreads on Improved Memory Model: Peter
Data collection, debugging, and final report writeup done by both members
OpenMP on original memory model: Peter
Improved Memory Model Implementation: Peter
OpenMP on Improved Memory Model: Sarah
Pthreads on Improved Memory Model: Peter
Data collection, debugging, and final report writeup done by both members